Datastore Parametric Risk¶
The Datastore Parametric Risk worker calculates the magnitude of a security's reaction to changes in underlying factors, most often in terms of its price response to other factors, creating a new datastore with the result of the calculations.
Parameters¶
The Datastore Parametric Risk worker must receive specific parameters in order to execute properly. When parameters are not set correctly it may cause the worker to not work as expected. This worker's parameters are separated in the following tabs: Input, Output and Advanced.
Input¶
The Input tab contains parameters which are consumed by the worker, in order to execute its calculations.
Portfolio¶
Set the target portfolio using Fixed Portfolio, Get Latest or Upstream Data variants.
Workspace¶
Set the research workspace of the portfolio using Fixed Workspace variant. The default is using the current workspace.
Property Selection¶
The property selection section contains the properties that will be included in the datastore.
Volatility¶
Select whether the volatility will be calculated or not using Boolean variants. The calculation returns options which can be chosen from the following items: Security, Standalone, Portfolio and Risk Factor.
VaR¶
Select whether the VaR will be calculated or not using Boolean variants. The calculation returns options which can be chosen from the following items: Security, Standalone, Portfolio and Risk Factor.
CVaR¶
Select whether the CVaR will be calculated or not using Boolean variants. The calculation returns options which can be chosen from the following items: Security, Standalone, Portfolio and Risk Factor.
Risk Factor Exposures¶
Select whether the Risk Factor Exposures will be calculated or not using Boolean variants. The calculation returns options which can be chosen from the following items: Security, Standalone, Portfolio and Risk Factor.
Output¶
The Output tab contains parameters that defines the worker execution results, and how it will be provided to downstream workers.
Name¶
Set the output datastore name using Template Text or Upstream Data variants. Default setting is the name of the input portfolio.
Date¶
Set the output datastore date using Fixed Date or Upstream Data variants. Default setting is the date of the input portfolio.
Workspace¶
Set the workspace in which the output datastore will be saved on the platform using Fixed Workspace. Default setting is the workspace of the input portfolio.
Tags¶
Set the output datastore tags using Fixed Tags or Upstream Data variants. Default setting is the tags of the input portfolio.
Persist¶
Select if the output datastore will be saved on the platform or be a transient one (temporary during workflow execution), through the following options: Transient or Create. The default is a transient datastore.
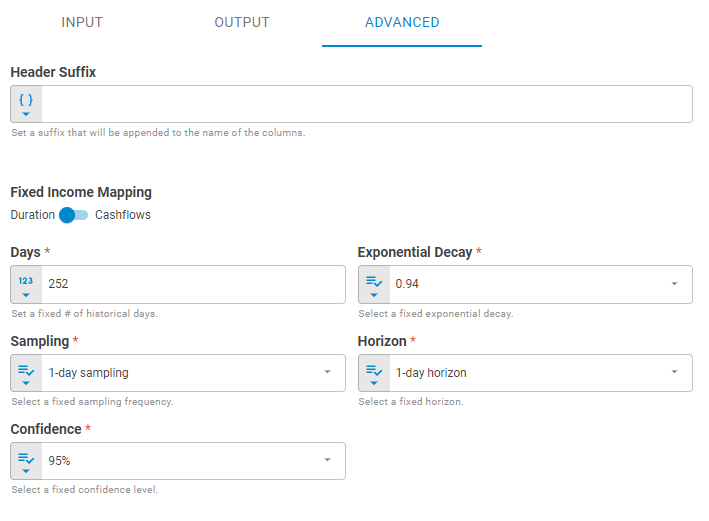
Advanced¶
The Advanced tab contains the header suffix and the set of parameters that will be used in the calculations.
Header Suffix¶
Set the header suffix that will be added to the end of selected properties columns in the datastore using Template Text or Upstream Data variants. The default is not using header suffix.
Fixed Income Mapping¶
For fixed income securities, when select is Cashflows, maps each cashflow event (interest, principal amortization) to various key points in the respective interest rate curve. When select is Duration, it uses the Macaulay duration to map bond price to neighboring key points in the respective interest rate curve. The default is using Duration.
Days¶
Number of historical business days used in Historical calculation using Number variants, the default is 252.
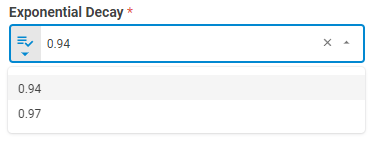
Exponential Decay¶
Weighting factor determining the rate at which "older" data enter into the calculation. The default is 0.94.
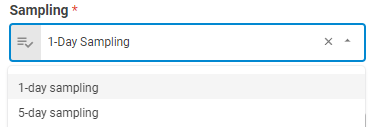
Sampling¶
Sampling represents the frequency that historical prices and rates (spreads) are collected in order to compute the invariant risk factors. In order to sample daily, use 1. In order to sample weekly (non-overlapping), pass 5. For various combinations between horizon and sampling click here. The default is 1-day sampling.
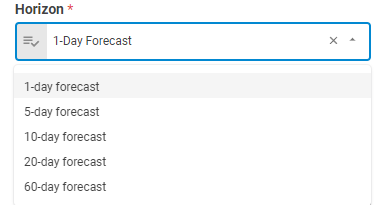
Horizon¶
Determines the Horizon for calculation. The horizon parameter produces a range of outcomes for each security via their underlying factors across specific date range. The default is 1-day Forecast.
Confidence¶
Determines the confidence level for calculation. The confidence interval produces a range of values with a defined probability that the value of a parameter lies within it. For example: if the confidence interval is 95% and the number of simulations is 10,000, we use only the first 5%, or 500 samples. The default is 95%.
Result¶
Once the worker finishes its executions successfully, it will return a result object containing the datastore to the workflow, which can be used by downstream workers. Below you can see an example of the datastore result object hierarchy.
- Datastore (datastore)
- ID (string)
- Name (string)
- Date (date)
- Tags (list of strings)
- Data (list of lists)
The Data component is composed of the columns common to all datastores, attributes and aggregations, including the selected properties columns. The possible columns added to the datastore are listed below.
- "factor_parametric_contribution_to_cvar_*"
- "factor_parametric_contribution_to_var_*"
- "factor_parametric_contribution_to_vol_*"
- "port_parametric_cvar"
- "port_parametric_var"
- "port_parametric_vol"
- "sec_parametric_contribution_to_cvar"
- "sec_parametric_contribution_to_var"
- "sec_parametric_contribution_to_vol"
- "sec_parametric_factor_exposure_*"
- "sec_parametric_no_sens_factor_exposure_*"
- "sec_parametric_standalone_cvar"
- "sec_parametric_standalone_var"
- "sec_parametric_standalone_vol"